.svg)

Agents are Brains. They Need Bodies.
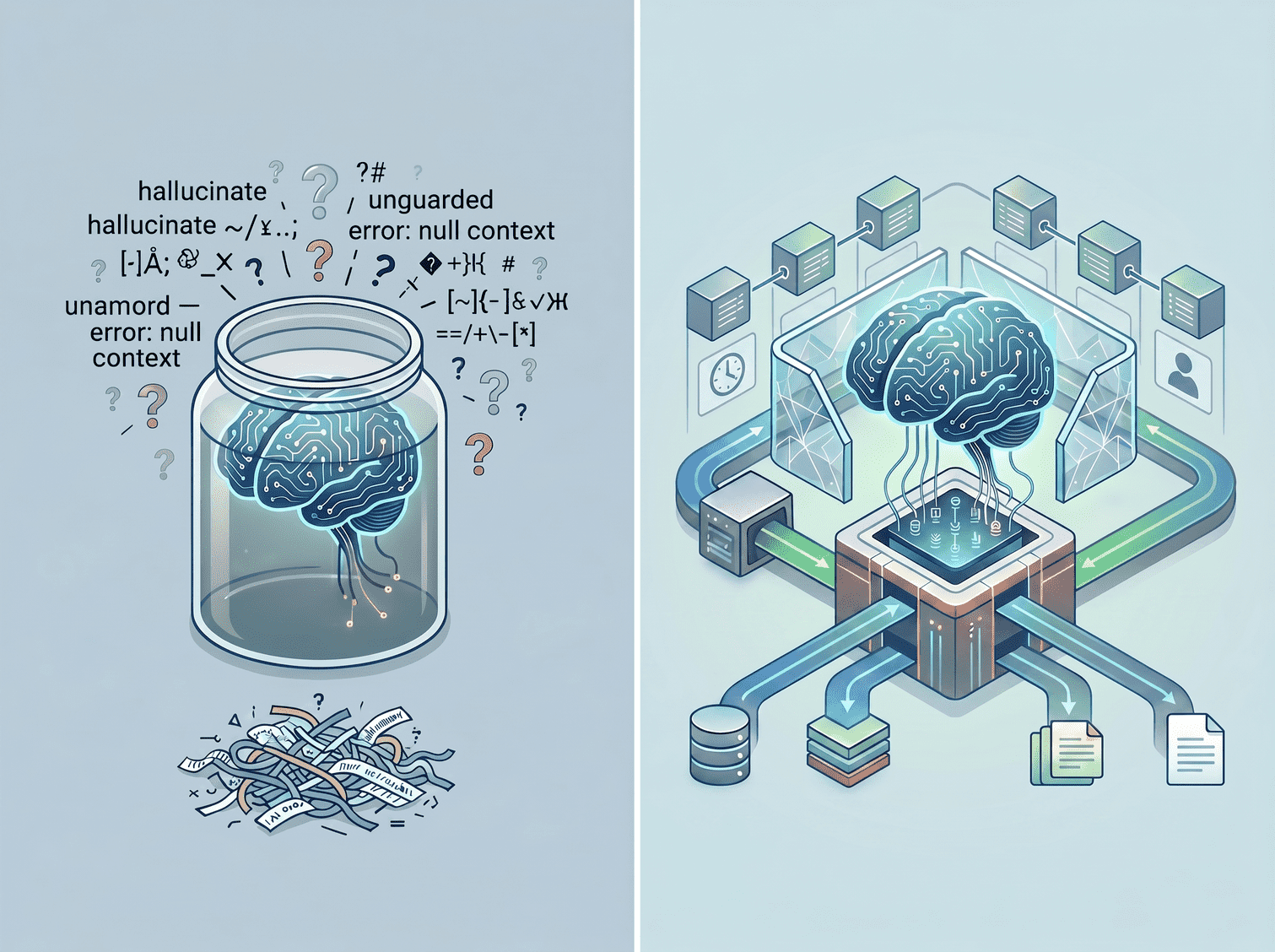
Agents are Brains. They Need Bodies.
Imagine a brain in a jar. It's able to reason and process information but it can't do anything with that capability because it has no way to reach the real world. No hands to act, no eyes to gather new information, no way to know what happened after the last thing it thought.
AI agents have the same problem.
The conversation around agentic AI has focused almost entirely on the brain i.e., the model, the reasoning, the prompting, the orchestration logic. This all makes sense, since the brain is the exciting part. But agents don't operate in isolation. They operate inside systems, on real data and in real workflows. If those systems aren't built to support them, the agent's intelligence doesn't matter.
The body is the infrastructure. And most teams haven't built one.
What agents can't do on their own
In most organizations when agents get deployed into a workflow, the agent has no reliable way to know what the organization actually knows. This becomes tribal knowledge. That is, the information that lives in people's heads rather than in systems. Which file naming convention does the team actually follow?
What does "processed" mean in this pipeline? Why does this dataset have a duplicate column? This is the knowledge gap that makes agents frustrating in practice. Contrary to popular belief, it isn't the failure of the model itself but the environment the model is operating in. Agents can't read minds, they read whatever they can actually access. And most of the critical context about how a workflow operates isn't accessible to them.
The result: agents that hallucinate conventions they can't verify, miss dependencies that aren't documented and produce outputs that are plausible but inaccurate.
The first half of the body: context
If you want agents to work reliably, the first thing to build is a curated context layer. Importantly, not documentation for human readers. Documentation for agents. A corpus of information that is structured and current with machine-readable representations of how your system works including what data exists, how it was produced, what the rules are and what's allowed.
Think of this as a Context Harness. The idea is that agents shouldn't have to reconstruct the state of the world from scratch every time they act. They should be handed a harness, a structured interface to the knowledge they need, so they can spend their capability on the actual task instead of guessing at the environment.
The second half: determinism
If context tells agents what the world is, determinism ascertains what they can safely do in it.
This is where most infrastructure discussions stop short. They get context right but don't enforce any structure on the agent's actions. The agent has good information but no constraints on how it uses that information, which means a mistake can propagate silently, a failed step can be retried with side effects and there's no way to know what the agent actually did without going back through logs.
Here are five properties that make an agent's operating environment work the way it needs to:
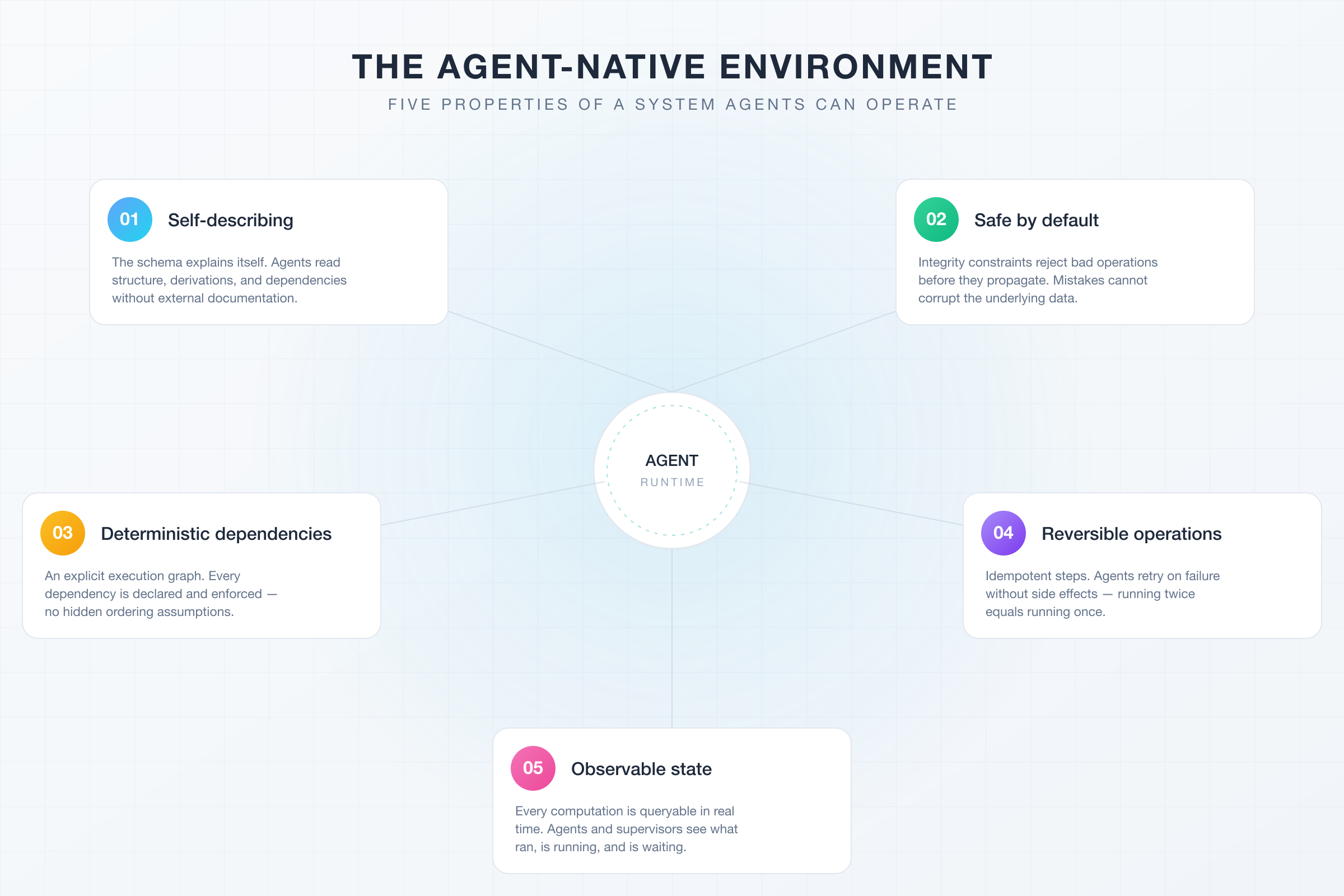
These five properties don't constrain what agents can accomplish, they constrain how agents can fail. That becomes the difference between an agent that augments a workflow and one that destabilizes it.
What this looks like in practice
With DataJoint, scientists design the schema deliberately, and that design is instantiated directly from the code that governs the data. Every arrow in the pipeline diagram is a real enforced dependency. An agent reads the schema and knows the full structure of the scientific process, from raw acquisition through every derived analysis, without needing to ask anyone. It can't produce an orphaned result because the integrity constraints won't allow it. It can retry a failed computation because operations are reversible. It can report on the status of any step because the state is observable.
The schema isn't a record of the science. It is the science.
The inversion
When agents operate inside an environment with a real context harness and deterministic infrastructure, their actions are auditable. Every step is traceable. Every output has a provenance chain. The human scientist doesn't have to trust the agent blindly; they can inspect what it did and why.
This inverts the usual framing around AI and rigor. We tend to assume there's a tradeoff: move fast with AI or maintain discipline without it. But that tradeoff only exists when the infrastructure isn't there. Build the body first and the agent's productivity and the system's rigor compound in parallel.
AI increases research productivity and rigor not despite operational discipline. Because of it.
That's the thing most teams miss when they deploy agents and then wonder why results are inconsistent. They bought the brain. They didn't build the body.
Related posts


When Scientific AI Forgets How It Got There

Neuropixels, Plainly Explained

AI and the Evolution of Relational Schemas

Updates Delivered *Straight to Your Inbox*
Join the mailing list for industry insights, company news, and product updates delivered monthly.
